2008-07-29
2008-07-28
轮询 vs. 事件
Evan Henshaw-Plath在OSCON2008做了题为“Beyond REST? Building Data Services with XMPP PubSub”的讲话,谈到RSS轮询检索导致的伸缩性问题。
Friendfeed网站使用RSS技术用来收集数据,就在2008年7月21日,为了得到45,754个用户最新图片信息,它就爬了2,975,981次,但其中仅有6,721的用户会上传图片。从这组数据看,平均对一个用户在一天里约查询65次,查看更新内容。假如用户习惯一天更新一次,对于这预计的一次更细,系统就要承担约443次(2975981/6721)的无效查询,压力增大443倍。更为糟糕的,RSS列表是有长度限制的,一般是20条,这意味着,如果用户上传了许多的话,系统记下的最多只能是20条。控制更新服务质量的方式,就是控制查询的频率和窗口大小(RSS清单项目最大数)。频繁的查询、大的查询窗口,对单个用户来说,更新的数据会更可靠,但对系统来说,系统的效用会更差。
问题的确严重,系统承担不必要的巨大压力,能源损耗也是巨大。为了这个问题,Henshaw-Plath讲话中提出了XMPP的消息传递的方法。是基于轮询(poll-based)?还是基于事件(event-based)?三四十年来,架构设计一直在这个问题上来回摇摆。
“轮询”,结构和实现方法是简单易上手,但以性能为代价;“事件”,效率的确好,但传递机制和维护措施复杂。一个事实是,无论是性能的代价,还是机制的复杂,它们都会导致系统伸缩问题。
Friendfeed网站使用RSS技术用来收集数据,就在2008年7月21日,为了得到45,754个用户最新图片信息,它就爬了2,975,981次,但其中仅有6,721的用户会上传图片。从这组数据看,平均对一个用户在一天里约查询65次,查看更新内容。假如用户习惯一天更新一次,对于这预计的一次更细,系统就要承担约443次(2975981/6721)的无效查询,压力增大443倍。更为糟糕的,RSS列表是有长度限制的,一般是20条,这意味着,如果用户上传了许多的话,系统记下的最多只能是20条。控制更新服务质量的方式,就是控制查询的频率和窗口大小(RSS清单项目最大数)。频繁的查询、大的查询窗口,对单个用户来说,更新的数据会更可靠,但对系统来说,系统的效用会更差。
问题的确严重,系统承担不必要的巨大压力,能源损耗也是巨大。为了这个问题,Henshaw-Plath讲话中提出了XMPP的消息传递的方法。是基于轮询(poll-based)?还是基于事件(event-based)?三四十年来,架构设计一直在这个问题上来回摇摆。
“轮询”,结构和实现方法是简单易上手,但以性能为代价;“事件”,效率的确好,但传递机制和维护措施复杂。一个事实是,无论是性能的代价,还是机制的复杂,它们都会导致系统伸缩问题。
预警系统,你好吗?
这则新闻说“我国将建房地产预警系统”:根据国家发改委的批复,“房地产预警预报系统”将依托互联网,建立涵盖40个城市节点的广域数据专网,构建包含40个城市节点的房地产市场基础信息数据库、监测指标数据库和信息发布共享数据库,建设基础数据库采集系统、基础数据库整合系统、监测数据分析系统、监测指标预警预报系统、监测与预警预报信息发布系统等应用系统等。
世上没有救世主,系统也一样,这类的经济预警系统,我国建了不少了,养了不少“纸上谈兵”的专家,也让大家都有项目分。大家知道,“风险”啦“危害”啦最容易说事,你怕了,你担心了,你也不明白,好,这就好办了。
那么,这里所说房地产风险究竟是什么风险?难道不是金融风险、不是信贷问题吗?如果没有银行贪婪地玩耍,房地产会走到如此地步吗?最近美国总统布什也戏言“次贷危机”,华尔街喝醉了,设计出自己也不明白的“金融产品”,人民上套了,银行上套,大家都上套了。
痛了,如果还不认真审视自己,发现自身的错误,纠正自己,痛苦还会再来,而且更加猛烈。
世上没有救世主,系统也一样,这类的经济预警系统,我国建了不少了,养了不少“纸上谈兵”的专家,也让大家都有项目分。大家知道,“风险”啦“危害”啦最容易说事,你怕了,你担心了,你也不明白,好,这就好办了。
那么,这里所说房地产风险究竟是什么风险?难道不是金融风险、不是信贷问题吗?如果没有银行贪婪地玩耍,房地产会走到如此地步吗?最近美国总统布什也戏言“次贷危机”,华尔街喝醉了,设计出自己也不明白的“金融产品”,人民上套了,银行上套,大家都上套了。
痛了,如果还不认真审视自己,发现自身的错误,纠正自己,痛苦还会再来,而且更加猛烈。
2008-07-25
消息?还是状态?
不管期望什么,服务计算的现实任务还是实现异构系统间的互操作。既然是为了互操作,两系统间总是要交换一些东西,那么这些交换的东西是消息呢?还是的状态?这便是SOAP(WS-*)和REST两个派别争执的核心。
在理想世界中, 消息和状态的变更是一回事情,只是视点不同。假如A按了B上的一个按钮,这便有了两个互补消息(e, e'),e使得系统B发生了状态变化,同理事件e'也使得系统A发生了变化。或许疑惑为何是两个互补的消息,不是一个吗?这也就想力有作用与反作用力,我推你一把,同样的力也反作用我自己。就服务范畴而言,消息e可以理解为请求,而消息e'理解为系统B处理事件e的响应。
再稍微复杂一点,假设A依次按了B的两个按钮。系统B因消息e由初始的s0变为s1,再因消息f变为s2; 系统A也相应地因消息e'由状态t0变为t1,再因消息f'变为t2。对于这两组互补消息(e, e')和(f, f'),很明显(e, e')发生于(f, f')之前。
至此,我理解发生顺序很重要,如果错乱,系统的状态肯定混乱。现实中总因素导致消息丢失,延时,因并发而冲突。这也就是为什么SOAP族的协议越做越复杂的一种因素。
尽管REST耦合性更为松弛,但你会发现,这种松弛令服务的自动发现和组合难以实现,还产生了令人恼火的资源发散,希望能够统一的处理,但这并不容易。
在理想世界中, 消息和状态的变更是一回事情,只是视点不同。假如A按了B上的一个按钮,这便有了两个互补消息(e, e'),e使得系统B发生了状态变化,同理事件e'也使得系统A发生了变化。或许疑惑为何是两个互补的消息,不是一个吗?这也就想力有作用与反作用力,我推你一把,同样的力也反作用我自己。就服务范畴而言,消息e可以理解为请求,而消息e'理解为系统B处理事件e的响应。
再稍微复杂一点,假设A依次按了B的两个按钮。系统B因消息e由初始的s0变为s1,再因消息f变为s2; 系统A也相应地因消息e'由状态t0变为t1,再因消息f'变为t2。对于这两组互补消息(e, e')和(f, f'),很明显(e, e')发生于(f, f')之前。
至此,我理解发生顺序很重要,如果错乱,系统的状态肯定混乱。现实中总因素导致消息丢失,延时,因并发而冲突。这也就是为什么SOAP族的协议越做越复杂的一种因素。
尽管REST耦合性更为松弛,但你会发现,这种松弛令服务的自动发现和组合难以实现,还产生了令人恼火的资源发散,希望能够统一的处理,但这并不容易。
2008-07-22
计划的代价注定要漠视品质
那些无论谈什么总是口口讲计划的,我称这些人是“计划主义者”。试图将质量控制和风险管理纳入计划范畴的努力都是徒劳的。好的计划者总是可以平衡进度、成本和资源,他是一个政客;好的质量者应热衷去追求他所认为的内涵,他是一个艺术评论家,甚至是个事无巨细挑剔的讨厌鬼;风险者却是一个天生持怀疑主义的行为谨慎的保守人士。
计划总是一个项目内的事,而质量和可能风险却总要超越项目。政客总会向他的支持者许诺,我有个计划,这回实现你们的要求。一段时间后,你会看到,那些有良心的政客履行了那些诺言,执行了那些计划,但你却发现,这些结果不是你所最急需的。
计划总是一个项目内的事,而质量和可能风险却总要超越项目。政客总会向他的支持者许诺,我有个计划,这回实现你们的要求。一段时间后,你会看到,那些有良心的政客履行了那些诺言,执行了那些计划,但你却发现,这些结果不是你所最急需的。
2008-07-21
最优有害?最终还是“简单”来支配!
这里报道了一项研究结果:
所有最优化进程都是局部的,或正因这种局部性,其最优化的结果也难复制和传递。
遗传突变为自然选择创造了赖以行事的原料。突变的短期命运相当清楚——制造更合适的生物体的突变能一代代持续下去,有害的突变更易于随着生物体消亡;突变的长期结果则并没有被进化生物学家很好地理解。新的研究表明,短期有利的选择可能会阻碍长期的进化。
...
Cowperthwaite解释说:“一些特征很容易进化——它们由突变的许多不同联合构成;另外一些特征则很难进化——它们由不太可能的遗传‘处方’构成。进化选择了容易的,即使它们并不是最好的。”
...
结果表明,生命确实由“容易”的特征所支配,或许以牺牲最好的为代价。
(报道所介绍的论文可在这里获得)
所有最优化进程都是局部的,或正因这种局部性,其最优化的结果也难复制和传递。
2008-07-17
文档工程
无论是企业单位,还是政府机关,只要是一个组织就会有林林种种的文档存在,可以这么说,没有这些文档的存在,组织是按制度无法运作的,运作过程也难以预计。看似简单的管理,事事却需巨细的处理,时间长了就令人抓狂。我曾参与一家飞机总机厂的知识工程,发现现实问题比想象的复杂,如标识文档和文档数字化,其所需工作量是原估计的二至三倍,而且最终成效也未必如愿,最后不了了之。
这里介绍了一种方法,或许有助于你在面上了解文档工程的相关活动。
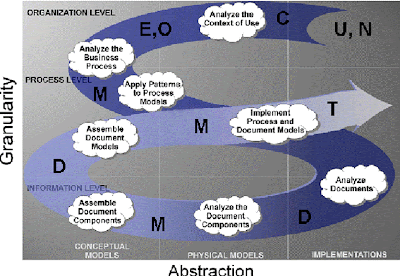 上图取自Bob Glushko的博文,图中字母D-O-C-U-M-E-N-T的含义如下:
上图取自Bob Glushko的博文,图中字母D-O-C-U-M-E-N-T的含义如下:
D -- 数据类型和文档类型
O -- 组织事务或组织过程
C -- 环境、上下文或相关事情
U -- 用户类型和特殊用户需求
M -- 所需的模型、模式或标准
E -- 相关企业、领域或生存环境
N -- 可以驱动企业的需求
T -- 技术、限制或机会
这里介绍了一种方法,或许有助于你在面上了解文档工程的相关活动。

D -- 数据类型和文档类型
O -- 组织事务或组织过程
C -- 环境、上下文或相关事情
U -- 用户类型和特殊用户需求
M -- 所需的模型、模式或标准
E -- 相关企业、领域或生存环境
N -- 可以驱动企业的需求
T -- 技术、限制或机会
2008-07-16
2008-07-14
顽皮的语言
计算机的自然语言处理,众所周知那是相当的呆板,其实作为实在的人,有时在“理解”上也会有所呆板,索性在反复怀疑和假设下,如果不在中途放弃的话,最终会理解的。下面是博主刘瑜在一篇博文使用的形式:
我开始理解是博主的意见共有一十二条,但看到是三条意见。博主更“可恨”的,还这三条意见分别标注为“1、4、12”,在我看来,以十进制阿拉伯数字书写,这是“断”号了。我还以为是RSS系统的问题,自动摘取部分内,打开原网站一看,还是一样的内容,再看附后的评注。呵呵,才知“上当”了。
博文中的符号“12条”存在符号的困户,必然被重新理解:
然而对于博文后面的标号“1、4、12”的理解,有人放弃了其原本的含义,直接当成一种纯符号,“第12条”就是一个名字而已。
这是一个很有意思的理解过程,起作用的不仅仅是所谓“语义”的东西,还有其它什么东西,那这是什么呢?
我“不明真相”,没多少看法,就12条:
1. ...。
4. ...。
12. ...。
仔细想来,这12个看法都跟...
我开始理解是博主的意见共有一十二条,但看到是三条意见。博主更“可恨”的,还这三条意见分别标注为“1、4、12”,在我看来,以十进制阿拉伯数字书写,这是“断”号了。我还以为是RSS系统的问题,自动摘取部分内,打开原网站一看,还是一样的内容,再看附后的评注。呵呵,才知“上当”了。
博文中的符号“12条”存在符号的困户,必然被重新理解:
- 有的人解释为“一两条”,但博文给出了三条意见,一种选择就是将“一两条”的“一个或两个”含义放松为“几个,最好越靠近一个或两个越好”;
- 有的人还理解为“1 + 2 = 3”,强调数量上的逻辑关系。
然而对于博文后面的标号“1、4、12”的理解,有人放弃了其原本的含义,直接当成一种纯符号,“第12条”就是一个名字而已。
这是一个很有意思的理解过程,起作用的不仅仅是所谓“语义”的东西,还有其它什么东西,那这是什么呢?
2008-07-13
高德纳谈开源和重用
高德纳在今年的一次访谈中,谈及开源和软件重用的话题,英文稿可从此处下载,热心人士的中文译稿参见此处。在这次访谈中,对“二进制级(或组件级)重用优于源码级重用”的质疑,这令人兴趣大增,高德纳本人更信任“可重编辑的代码”。
(下面摘抄访谈部分内容)
(下面摘抄访谈部分内容)
For example, open-source code can produce thousands of binaries, tuned perfectly to the configurations of individual users, whereas commercial software usually will exist in only a few versions. A generic binary executable file must include things like inefficient "sync" instructions that are totally inappropriate for many installations; such wastage goes away when the source code is highly configurable. This should be a huge win for open source.
例如,开放源代码能带来数以千计的二进制包,可以完美地针对每个独立用户进行配置,但是商业软件通常只有几种版本。一个通用的二进制可执行文件必须包含很多指令来“抹平”不同运行环境间的差异,这对于很多安装环境来说并不合适;然而源代码是高度可配置的,因此这种浪费也就随之消失了。这是开源软件的巨大优势。
I don’t want to duck your question entirely. I might as well flame a bit about my personal unhappiness with the current trend toward multicore architecture. To me, it looks more or less like the hardware designers have run out of ideas, and that they’re trying to pass the blame for the future demise of Moore’s Law to the software writers by giving us machines that work faster only on a few key benchmarks! I won’t be surprised at all if the whole multithreading idea turns out to be a flop, worse than the "Itanium" approach that was supposed to be so terrific—until it turned out that the wished-for compilers were basically impossible to write.
我不想回避你的问题。也许我个人的一些观点会为当前流行的多核架构趋势泼一盆冷水。在我看来,这种现象或多或少是由于硬件设计者已经无计可施了导致的,他们将Moore定律失效的责任推脱给软件开发者,而他们给我们的机器只是在某些指标上运行得更快了而已。如果多线程的想法被证明是失败的,我一点都不会感到惊讶,也许这比当年的Itanium还要糟糕——人们基本上无法开发出它所需要的编译器。
The machine I use today has dual processors. I get to use them both only when I’m running two independent jobs at the same time; that’s nice, but it happens only a few minutes every week. If I had four processors, or eight, or more, I still wouldn’t be any better off, considering the kind of work I do—even though I’m using my computer almost every day during most of the day. So why should I be so happy about the future that hardware vendors promise? They think a magic bullet will come along to make multicores speed up my kind of work; I think it’s a pipe dream. (No—that’s the wrong metaphor! "Pipelines" actually work for me, but threads don’t. Maybe the word I want is "bubble.")
我今天所用的机器有两个处理器。而我只有在同时运行两个独立的作业时,才会用到这两个处理器;这样很好,不过每周这种情况只会发生几分钟而已。如果我有四个、八个甚至更多的处理器,我同样得不到任何好处,想一想我是做什么的——我几乎每天每时每刻都在使用计算机。所以,我为什么要为硬件供应商承诺的未来而高兴?他们认为多核的到来可以为我的工作提速,我认为这是“白日梦”(pipe dream)。(不——这个比喻不准确!我是会用“Pipeline”的,但是不会用线程。也许我应该说这是个“泡影(bubble)”)
That question is almost contradictory, because I’m basically advising young people to listen to themselves rather than to others, and I’m one of the others. Almost every biography of every person whom you would like to emulate will say that he or she did many things against the "conventional wisdom" of the day. Still, I hate to duck your questions even though I also hate to offend other people’s sensibilities—given that software methodology has always been akin to religion.
我通常都是建议年轻人要相信自己的判断,而不是其他人。我就是“其他人”中的一员。大概每一位你要效仿的“伟大人物”的传记上都会记载,他或她曾经向当时的“传统智慧”发起过挑战。 虽然如此,我并不想回避这个问题,尽管我也不想触动其他人敏感的神经——有一种软件方法学已经类似于某种宗教了。
I also must confess to a strong bias against the fashion for reusable code. To me, "re-editable code" is much, much better than an untouchable black box or toolkit. I could go on and on about this. If you’re totally convinced that reusable code is wonderful, I probably won’t be able to sway you anyway, but you’ll never convince me that reusable code isn’t mostly a menace.
我还必须承认我对“可重用代码”的流行保有强烈的偏见。对我来说,“可重编辑的代码”要远远胜于一个无法触及的黑盒或工具集。就这个问题我还可以不断地说下去。如果你对可重用代码深信不疑,我可能丝毫无法动摇你,但是你也无法让我相信,可重用代码并不总是麻烦制造者。
2008-07-07
业务偏模型
无论是面向服务体系结构(SOA),还是业务进程管理(business process management)都有一个共同根基,这就是业务模型。只有健全的业务模型,才可能使得业务愿景得以实现。但现实令人困窘:
- 我们很难有一个全貌的业务模型,即使努力的完成它一部分,也发现,在宏观框架,它是井井有条,颇有成就感,但扎入微观的细节,才发现那是有多么的复杂,看似冗余但却必须,这些细微差别,专家是侃侃而谈,却令旁人昏昏欲睡;
- 业务模型总是要超脱那些具体实例业务应用系统的,这种超脱地位是不能动摇的,自业务应用系统运转后,同床异梦就开始,总是走不到一起,对于这种混乱我们束手无策,尽管有人大呼该治理(governance)了;
- “敏捷”是一种时尚,不时的新的业务模式会突现一种,在竞争名义下要去适应它,但我们很快就会发现,将合并的业务模型中,这不是一件轻松的事情,要冒着弄脏数据的风险。
我一直在怀疑,那个“健全的业务模型”是否会存在。或许无论处于何时,使用何种方法,所见的只是部分,那些逻辑完全的业务模型都是一种偏模型(partial model)。如果每一个应用系统都是这些偏模型的实例,那么这些偏模型是如何“粘”接在一起的呢?或许存在一个连续的空间,某个偏模型就是某个投影,那么这个“连续”的空间是什么?!
2008-07-03
非结构化数据面临的风险
企业的数据绝大部分是非结构化数据,这些数据也面临了不少风险,援引此文的调查,这些问题可归纳为:
- 没有具体的访问控制策略,存在滥用的风险。
84%的受访者则说,在他们的公司,太多的员工可以访问企业里关键的非结构化数据,约76%的人表示他们的公司没有设置具体的方法去控制哪些员工可以访问具体的非结构化数据。
- 缺乏跟踪非结构化数据的手段,易失去控制能力。
大约61%的受访者表示他们无法跟踪哪些用户在访问具体的非结构化数据,91%的人则表示,由于错误的管理政策,以及缺乏能解决这个问题的可用的存储工具,他们的组织没有能力去确定数据的所有权。
- 意识到这些风险,却束手无策。投入资金,亦难以见效。
虽然IT经理们继续在存储技术上花费大量的金钱,以满足迅速增加的结构化数据,许多人都承认非结构化数据的复杂性使得人们难以掌握它。
Ponemon 说:“我们发现,不是IT经理不愿意去花钱,而是他们真的不知道怎样去解决非结构化数据的复杂性,这是一个知识层面上的问题。”
订阅:
博文 (Atom)